Advice
Nov 27, 2023
Machine Learning behind Artificial Intelligence

Introduction
Since the launch of “ChatGPT” artificial intelligence has become a term known to the masses. Prior to that most people may have heard it in sci-fi or may have treated it as jargon in a podcast. Today however most common people, even outside computer science and related fields have experienced what can be achieved by building “intelligent” systems. At this point, I would like to give a brief overview of “Machine Learning” which is a key enabler for “Artificial Intelligence”.
AI vs Machine Learning
“While artificial intelligence encompasses the idea of a machine that can mimic human intelligence, machine learning does not. Machine learning aims to teach a machine how to perform a specific task and provide accurate results by identifying patterns.
Let’s say you ask your Google Nest device, “How long is my commute today?” In this case, you ask a machine a question and receive an answer about the estimated time it will take you to drive to your office. Here, the overall goal is for the device to perform a task successfully—a task that you would generally have to do yourself in a real-world environment (for example, research your commute time).
In the context of this example, the goal of using ML in the overall system is not to enable it to perform a task. For instance, you might train algorithms to analyze live transit and traffic data to forecast the volume and density of traffic flow. However, the scope is limited to identifying patterns, how accurate the prediction was, and learning from the data to maximize performance for that specific task.”
- Google Cloud
In my understanding, while machine learning is an entire system that is required to enable a machine to behave in some intelligent way to solve a purpose, machine learning is the core algorithm running background. It is highly likely multiple machine learning algorithms are working in tandem to enable a single prominent “AI” machine or a service.
What is machine learning?
Machine learning is the science of identifying patterns in existing data and coming up with a black-box function that defines a boundary on the patterns found in the data. These boundaries are then used to guess characteristics of a completely new data point of which we don't know the reality in the present.
For example: Forecasting the price of a stock, deciding what an autonomous car does given the current state, predicting size of clothes of a person from a photo/video, recommending movies to a user.
It should be noted that most machine learning algorithms work around some kind of optimal probability of being accurate i.e. it is almost certain that for some data points it will be wrong. That brings us to a place where they are not the best solutions for all kinds of problems, rather some specific types of problems with certain characteristics.
Characteristics of Ideal for a Machine Learning Solution
A problem that may have an ideal solution have the following characteristics:
There is access to enough previous data that can serve as examples of reality and can be used to train machine learning models.
There is no definite way of deducing actual truth for the current data point and we may only know the truth in future when the event actually occurs or some kind of manual inspection is conducted.
It's ok to be wrong sometimes and the solutions built over these are resilient to them. You would want to let a doctor take a final call on your disease and not a machine learning model. Here a machine learning model can be an assistant to the doctor though.
Typically ML solutions are expensive to build and maintain, and the resultant system justifies the financial outcome for it.
Examples of Ideal Machine Learning Problems
Stock Forecasting - Forecasting the value of stock is one of the most popular problems solved using different machine learning techniques. There is enough past data available to provide examples to the ML model to learn different patterns and make predictions on future data. While it's expected that sometimes the algo will be wrong, if the accuracy is high enough there is immense monetary gain in building this system. This would be an example of supervised machine learning technique.
Decision making for Autonomous Cars - It's well known the benefits of having autonomous cars: safety, independence and movability. There is enough data available to build simulations to allow autonomous cars algorithms to learn to make optimal driving decisions and while driving cars if the model does not mess up in a big way (resulting in a crash or another mishap) there is some wiggle room for errors. This is an example of reinforcement learning.
Examples of Non-Machine Learning Problems
Determining User Log-In Status - Login status of a user is a definite state and can be determined with 100% accuracy using an auth mechanism. Building a ML model to do something like this will be invariably incorrect and a bad design.
Determining if a dog is Happy or Sad - While the problem is solvable using machine learning techniques it is not obvious that this application will be commercially viable and generate valuable enough information to justify the infrastructure cost.
High Level Flow of Solving Machine Learning Problems
Machine learning or Artificial Intelligence is nearly reaching to be a century old field. Over the last 3 decades ML algorithms have matured and are now being almost all mid-level to large scale existing in the world. This maturity has built several best practices and systematic approaches now exist to build ML based solutions reliably. In general, I would say most problems can be solved using the following high level steps:
Identify the problem, and clearly define the ideal state.
Identify if the problem meets the criteria to be solved using a ML algorithm.
Build and Test ML model that would solve the problem.
Deploy the problem in a service which allows the model to predict data on future flows.
Monitoring Feedback and Maintenance of the model to remain relevant as the pattern in the data changes overtime.
Defining the problem statement
This is more a business oriented process rather than directly related to implementation of tech solutions to it. Generally it is best to define the problem or gap your business is facing and how an ideal solution looks like. At this stage you are expected to not really worry about implementation details and what a solution may look like.
Usually at this stage relevant stake holders like business leaders and product managers discuss and document the current state and the ideal state. Also it's a good idea to discuss why the new state will be a better place and probably come up with some kind of time and monetary budgets for the same. These budgets help determine the stakes for the project and eventually help choose the best solution.
For some consumer projects or products with external clients it will be a good idea to run some bit of UX research to justify the product.
Evaluating If Machine Learning Solution Makes Sense
Once there is a clear problem statement, it is required to evaluate its feasibility for a possible AI/ML solution. Generally AI/ML solutions are less predictable and costlier compared to a clear software solution if it's possible to implement one.
It would be required at this stage to see if there is access enough to data that can intuitively help you build machine learning solutions. For example, predicting a price of a house in a particular city, you might want to know at what price other houses were sold and what were the major factors that contributed to the sale price. Identifying this data and building an intuition of what pattern an ML algorithm should learn is the first concrete step towards ML.
Build and Test ML Model
This is the core step of building a ML model. Some standard steps in sequence that would be followed will be the following:
Data Preprocessing
Model Training
Model Evaluation
Data Preprocessing - Appropriate data in machine learning is more critical than a specific machine learning model. In case representative and relevant data is collected and used to train a ML model, it's possible more than one type of model gives you comparable results. Vice-versa is also true, if data is not appropriate to the problem we are trying to solve, even the latest models will fail to give you results. This gives rise following few fields which are vast enough to make life-long career in them:
Data Collection - This part has more to do with traditional software engineering, big data and data warehousing as compared to AI/ML. At this stage data has to be collected and aggregated from various streams of data. Aggregation happens of multiple streams and related data is stored together.
Few design considerations that should be kept in mind while designing your solution would be: Methods of data ingestion: HTTP based API, live streaming or offline bulk ingestion
Finding relevant storage solutions which justify the use case. Eg. storage can be done in magnetic disks, vs files in services like s3, sql databases or even something highly available and lighting fast distributed databases like GCP Spanner or AWS DynamoDb. This selection will depend on the use case of latency to access the data and availability of the same. Obviously this has to be limited by project budgets.
Quality of the input data and how representative of the events we are trying to predict using machine learning.
Collecting large amounts of data and aggregating multiple input streams can give immense power to anybody who has access to it. Using this data several insights can be drawn that can be used maliciously, which make the moral liability of the business to have sound security mechanisms in place.
“With Great Power Comes Great Responsibility” - Voltaire and In Popular World Spiderman’s “Uncle Ben”It should be noted that with AI getting more popular it becomes imperative that implementers of AI take the responsibility of making it equitable and safe for everyone.
Several large companies just provide access to high quality data sets collected over time: Kaggle, AWS Exchange, Database etc, which can then be consumed to build and train AI systems.
Data Cleaning and Preparation - This stage usually goes in tandem with the previous stage where we remove incomplete, inaccurate data that may wrongly influence the data. You might want to remove data during a certain duration as you might have realised it would represent an outlier situation. Some of the key things done during this phase are following:
Detection and Handling of missing data(null, NaN, blanks etc). Some ways of handling this would be deletion or completing the records. In some cases representative data is generated, however it does create a risk of a model showing biases of the user.
Deduplication of data.
Data transformations.
Outlier Handling
Feature Engineering - This is the beginning stage where the science of ML gets applied and while software provides its own benefits, the knowledge of statistics, data manipulation, advanced mathematics and data visualization techniques become of key importance.
The goal of this stage is to extract features from data and transform them in such a way that there is some pattern in them such that it can be used to train models.
Some of the techniques used in this stage are the following:
Feature Encoding: All features are represented as numbers, such that they can be easily used in the ML models.
Feature Scaling: Ensuring that all the features are in comparable range when compared to each other and typically a decimal between 0-1. This allows faster training of ML models and also removes the risk of one feature over powering other features although there are techniques to keep that in check. Some ways to do feature scaling is: mean normalization, z-score normalization
Adding new features: It’s possible that while the existing features are not immediately differentiating enough to create a pattern, with some transformations a pattern can be formed. A way to add new features is polynomial regression, in which higher order polynomials of existing features are used as new features.
Removing some features: Some of the features may not have a significant enough impact on the decision making. In such cases adding these features only leads to slow downs in training and inference. A way to do this is Principal Component Analysis (PCA).
Some libraries for data visualization are Matplotlib, Pandas Visualization, Scikit-plot etc….
Model Training - Training a model basically refers to providing a ML model with enough examples of existing feature rich data such that models using some mathematical formulas are able to learn and generalize patterns such that the same patterns can be applied to new data and predict something about it.
Usually such patterns are not obvious and in some cases do fail to be accurate.
On the basis of problem statement, available and project budget an ML model has to be chosen wisely.
At a very high level ML models are widely divided into following categories:

Supervised Learning - In supervised learning a model is fed with sufficient examples of what is the correct output given an input feature set. Based on this, the ML model tries to determine the decision boundaries for a classification problem or estimate a value for a continuous value problem/non-classification problems (e.g. predict the max temperature for coming Tuesday).
Overtime several approaches have developed to train a model efficiently and broadly can classified as follows:
Traditional Supervised Learning - In a traditional supervised learning algorithm, training data consists of examples of feature sets and correct value of the instance. Usually this data is collected with significantly more human-touch and thus the models are seldom retrained often. Rather once the model training is complete, these models are deployed to use, and monitored for any regressions. They are retrained only if a significant amount of regression is seen. They are usually good use-cases where the data pattern is not going to change often.
Few examples of such ML models would be following:
Logistic/Linear Regression: These are few of the earliest ML models developed. Logistic Regression is used for classification purposes while Linear regression is used for predicting a continuous value. Usually these models are significantly simpler than modern ML models and can be useful for significantly simpler ML use cases. However these models became the building blocks for modern day neural networks.
Decision Trees or Random Forest: Here we split the data using the help of tree data structure and rules. Decisions are made at the leaf nodes of a tree. Decision trees can be notoriously big and difficult to maintain for evolving patterns. Over time the use of these ML algorithms has significantly come down for modern use cases. Some places where they were extensively used were insurance claim processing engines.
Support Vector Machines or SVM: These ML models remain a real challenge to Neural Net until at least 2012. These models are powerful enough and significantly cheaper than a large-scale Deep Neural Net. The basic idea is to find a hyperplane that best fits the data in the dimensionality of the data.
Deep Neural Networks(DNN): Some deep neural networks like CNN and RNN are trained using traditional supervised learning. Deep Neural Networks are made of multiple layers of interconnected neural networks consisting of neurons (a single neuron is used in simpler regression models). Today DNN is spreading over billions of connected neurons and the applications that can be built over them is just mind rattling. These models are usually expensive and computationally heavy.
Semi-Supervised Learning - A very common problem in ML is that there is a small subset of high quality data that is labeled with an expected value and a large data set which is not. In such cases, labels for unlabeled data are generated and then supervised learning is applied to it.
Generally other ML models/approaches like unsupervised learning are used to generate the labels. It is essential that good checks are applied before training so that model is actually representative of the real world.
Self-Supervised Learning - These are generally generative ML models, where they try to predict the next value given the sequence till now. Some of the LLMs are trained this way. The idea is to use the existing data, a small part of the data and predict the next value in the sequence and compare against what is actually present in the data. Thus data itself is acting as input and label for the model and hence the term “self-supervised”. Avoiding regression overtime and having truly representative data in such cases become imperative and challenging at the same time. Usually the data for such scenarios are in TB and may also reach PB.
Common Techniques and Concepts in Supervised Learning
Activation Functions - These are mathematical functions that are applied to the output of neurons in regression models and Neural Networks. They bring in the non-linearity in the decision boundaries and hence without them, even the largest of the NN will just be highly inefficient linear regression models!
Some of the common activation functions are: Sigmoid, Rectified Linear Unit (ReLU), Linear Activation Functions(LAF).Error or Loss Function - A loss function helps determine for individual instances in the training data how far are model predictions from the actual values/labels. For different ML models different loss functions have proven to be effective. Some examples of loss functions would be: Squared Error or logistic loss function
Cost Function - While the loss function applies to only a single instance, the cost function calculates the net error across entire training data. The goal of a machine learning model is to minimize the cost function value with respect to all the learning parameters such as model weights. To minimize weights, partial differential of the cost function is done wrt learning parameters. This enforces the loss function to be continuous across a range of values. Also as we minimise cost function we try to find minima by wiggling the learning parameter values, and hence loss functions that result in a convex graph are easier to find optimal values.
Gradient Decent - Gradient descent is the universal mechanism to minimize a cost function and optimally train a ML model. GD uses a learning rate constant to converge the model to a global minima. It can tend to be slow when being applied to large training data sets.Overtime optimized versions of GD have been developed like Stochastic Gradient Decent and Adam’s Algorithm.
Backpropagation - Backpropagation is the algorithm behind how neural networks update weights across multiple layers based on the error produced at the last layer or the output layer. This algorithm is one of the most important reasons we have deep neural networks and what brought NN back from cold storage.
Transfer Learning - Transfer learning is the process of picking up weights/architecture of a pre-trained model (usually trained on a much larger data set and broader use case) and creating a new model by training it for a more specific use case, reducing the learning time significantly. Broadly there are 2 ways of applying transfer learning:
Replace the last layer of the neural network and retrain the model.
Reset the weights of the last layer of the neural network.
Unsupervised Learning - In case of unsupervised learning, there is a large data set however it's not labeled. One may like to extract information from this data sets like:
Clustering: How many groups or clusters you can form within data. Based on this you can then assign a cluster to incoming data. One of the algorithms to do so is K-Means Clustering.
Anomaly detection: Given the data that exist how probable it is that new data should exist. This approach is used in several security platforms. This helps flag anomalies and then later manual inspection may be required.
Recommender Systems: Based on the user history what movie will users like to see next or what they would buy next.
Reinforcement Learning - Reinforcement Learning is for AI applications that do not have a fixed way to solve problems and achieve the goal. Generally the environment is very dynamic and it's difficult to define it very accurately in the code. In such scenarios:
“The model learns via trial and error, by receiving rewards or penalties after taking some action and moving from one state to another. The model is trained to maximize the rewards and minimize the penalties.”
Following concepts apply to reinforcement learning:
State: It's defined as the set of values required to accurately describe the exact situation of the object that is going to be trained. Usually these values are observed with the help of a bunch of sensors.
Action: An object can take a bunch of actions to move from one state to another.
Rewards and Penalties: An object as it reaches a terminal state (good or bad) is awarded points and when in training an iteration of training comes to end.
Discount Factor: As an object moves from one state to another, the time and effort it spent is calculated as a discount factor reducing the reward it can achieve.
Policies: A set of rules which allows the object to choose an action from the current state. Reinforcement learning is about learning the set of rules or policies.
Reinforcement learning algorithms are based on the “Markov Decision Process” where the future will only be dependent on the current state and the action taken here.
State Action Value Function - As the model learns the environment by several trial and error, it computes and records the value of an action in a particular state and can be represented as:
V(s,a) => value of maximum reward that can be achieved by taking action “a” in the state “s”.
Bellman Equation - “A Bellman equation, named after Richard E. Bellman, is a necessary condition for optimality associated with the mathematical optimization method known as dynamic programming.” - Wikipedia
Mathematically, the Bellman Equation is written as (source):
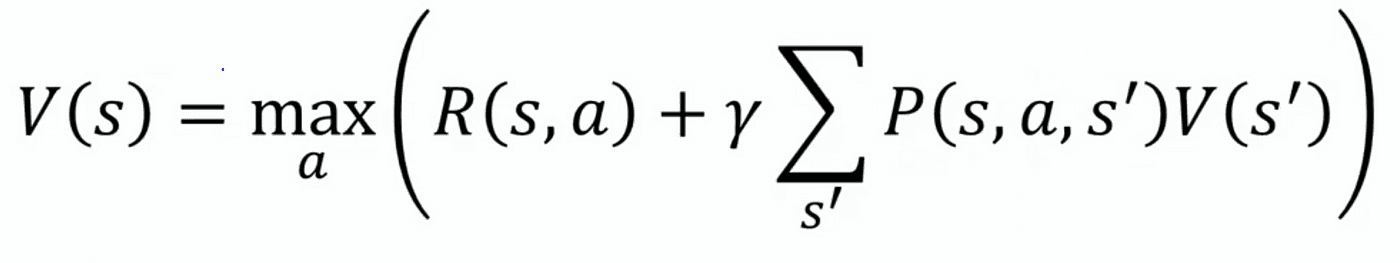
Where:
V(s): The value of state sss, which represents the long-term reward of being in that state.
R(s,a): The immediate reward received for taking action aaa in state sss.
γ: The discount factor (between 0 and 1) that determines the importance of future rewards compared to immediate rewards.
P(s′∣s,a) The probability of transitioning to state s′ from state sss by taking action a.
maxa: The optimal action that maximizes the expected value of future rewards.
Bellman equation allowed an effective way to formulate reinforcement learning into a mathematical model and then train a ML model to define the best policy.
Basic Steps to Train NN using Reinforcement Learning
Initialize Neural Network with random guess of V(s,a)
Taking thousands of random actions and recording the values of s, s’, a and R(s,a).
Store an arbitrarily large number of records (lets say 10k) of the most recent values.
Use these values to train a Neural Network as a training data set.
Updated weights of NN define a Vnew(s,a)
Repeat steps 2-6 for several iterations lets say 1000 or something.
Deepseek were able to significantly bring down the cost of pre-training LLM using reinforcement learning rather than self-supervised learning.
It should be noted that field Reinforcement Learning is still maturing and has very few applications using them as ML algo. However it has proven to be useful till now and many large scale real world applications are expected to be using it.
Model Evaluation
Model evaluation is the process of estimating how the model is performing and should it be used for the purpose of an AI application that is being built. Several sophisticated methods have been developed to evaluate the performance of a ML model and most of them can be applied irrespective of the ML model that is chosen to do the predictions.
Steps to evaluate model
Divide the initial data into 3 mutually exclusive data sets namely training, cross validation and test data set.
Use the training data set to train different ML models.
Evaluate the models against the cross validation data set and choose the best performing model.
Use the best performing model and test data set to compute final performance numbers of the model.
How to calculate model performance?
Usually accuracy has been broadly used as a measure in several systems to evaluate performance. However in the case of machine learning it can be highly deceiving. For example, imagine in a binary classification problem a model always tells yes. Depending how representative the test data set is for both the classes, model accuracy keeps varying. In case the yes is more than 99% accuracy will also be 99%, but in reality the model will be useless.
Accuracy is still a good estimate for predicting non-classification problems (or continuous value problems). Other measures that can be used here are MSE, RMSE etc.
Before we dive into what can be used for classification problems lets understand some basic terminology:
True Positive (TP): When the model predicted the class correctly and in case of binary classification problem a yes is predicted.
False Positives (FP): When the model predicted the class incorrectly “Yes” in case of binary classification problem.
True Negative (TN): When the model predicted the class correctly as “No” in case of binary classification problem.
False Negative (FN): When the model predicted the class incorrectly “No” in case of binary classification problem.
Some classification problem evaluation measures:
Precision: What are the chances that a predicted value is accurate. Basically what are the chances that a predicted “Yes” is yes not “No”.
Precision = TP / (TP + FP)
Recall: What are the chances that predicted “Yes” are the only “Yes” and we have not predicted an actual “Yes” as “No”.
Recall = TP/(TP + FN)
F1 score: While recall and precision are fairly resilient to data biases, they do not give a singular score to evaluate the mode which can then be minimized across models. F1 score combines precision and recall to compare multiple models against each other.
F1score = 2*Precision*Recall/(Precision + Recall)
Overfitting or Underfitting
It's possible that a model is not trained appropriately and has either High Bias (Underfitting) or High Variance (Overfitting). Underfitting or High Bias occurs when a model does not learn the pattern in the data enough and in such scenarios will tend to have high errors in both training and testing data. Over-fitting or High Variance occurs when a model becomes too complex and has learned patterns in the training data by building extremely complex decision boundaries. This leads to models accommodating even the outliers in the training data. This causes very less errors in training even touching almost zero and high errors in the test data. A model is just right when the training error and test error are approximately equal.
In regression models one can avoid over-fitting by including a “regularization term” in the loss function which penalizes complex models and large weights, also ensuring the model is not overly reliant on a single feature in the feature set.
Some actions that you can try to reduce errors:
Get more training examples.
Try a smaller features set and remove irrelevant features.
Try adding more features, maybe higher order polynomials of existing features.
Decreasing or Increasing regularization constant.
Deploying Machine Learning Models
Usually once the model is trained and has been evaluated to be good enough for the purpose of the AI application it is deployed behind a service. Some models are used for offline predictions and may not be required to be running on an online server. Several cloud providers have made it easy to deploy a ML model quickly and use them in the application.
It is possible predictions in a ML model can be slower than a typical pure S/W based services, and thus service architecture should accommodate for that. This is more a Software Engineering problem than a ML problem
Monitoring and Maintaining Machine Learning Services
Machine learning models can overtime deteriorate for various reasons. It is imperative that a feedback mechanism exists that allows us to actively evaluate a deployed solution. Models should be retrained regularly on the latest data, such that they are learning the latest trends in the data and are not outdated.
As technology and research progresses better models are being developed frequently which are faster and accurate compared to older models, and being on top the current technology will help your service to remain relevant and competitive to the market. Services should be built in such a way that these models can be easily replaced safely.
Closing Remarks
Machine learning and Artificial intelligence are vast fields and may take several lifetimes to learn them in their entirety. To be able to deliver solutions in this space, one should be generally aware of the concepts in the field and pick problems to solve. As you solve more problems you will be able to deep dive into relevant topics. There is enough material available online both paid and free. Let's get going and see what is the next big thing that will break the internet!

